7 Tage, 7 Nächte
In den letzten sieben Tagen des Schyndy-Jahresbeginns bin ich insgesamt 14+15+16+17+18+19+20 = 119 km gelaufen. Diese sieben Tage waren aber keine Kalenderwoche. Die drölfzig von mir genutzten Analyse-Tools/-Dienste bieten jegliche wochenbasierte Auswertung allerdings immer nur auf Kalenderwochen-Basis an. Daher wusste ich zwar im Vorfeld, dass meine bisher weiteste Kalenderwoche gute 102 km hatte. Aber: Wenn ich nun beispielsweise von Donnerstag in Kalenderwoche 1 bis Mittwoch in Kalenderwoche 2 – sieben Tage lang – jeden Tag 20 km laufe, sind das 140 km in einer Woche. Trotzdem würden KW1 und KW2 nicht unbedingt in den Statistiken herausstechen.
Ich wollte also – da mir klar war, dass die 119 km ein neuer Rekord sein müssen – endlich herausfinden, was bisher meine weiteste Woche überhaupt war. Spoiler: Mein leiser Verdacht, dass es nicht die KW-basierten 102 km sind, hat sich bestätigt.
Erster Schritt: Ich brauche alle meine Läufe in einem einfach auswertbaren Format. Nach kurzer Recherche hat sich der CSV-Export bei Smashrun als beste Quelle erwiesen. Eine Zeile pro Lauf, und fast noch wichtiger: Mit korrekter, lokaler Startzeit. Da ich oft kurz nach Mitternacht den Lauf eines Tag erledige, müssen die Zeiten im Datensatz wirklich denen entsprechen, die ich beim jeweiligen Lauf auch auf meiner Uhr hatte. Das ist komplexer als man meinen möchte, weil wir immer noch solchen Quatsch wie Zeitzonen und Zeitumstellung haben.1
Ich werte ungern in Excel/Numbers/Spreadsheets aus, also importiere ich das CSV stattdessen in meine PostgreSQL-Datenbank:
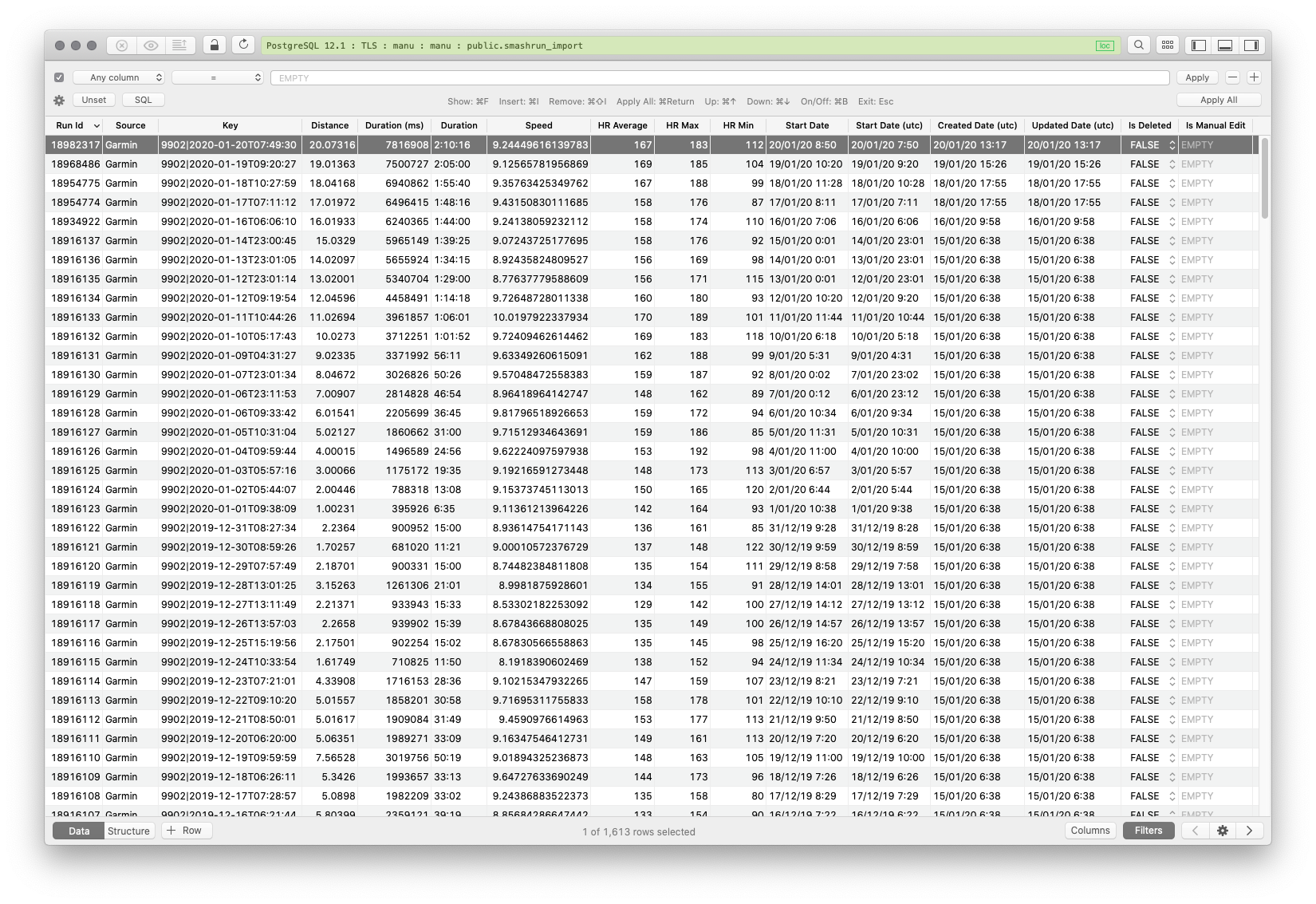
Das Datumsformat ist aktuell noch komplett unbrauchbar, außerdem interessieren mich für die weitere Auswertung lediglich der Tag und die Distanz, also erzeuge ich erstmal eine bereinigende View mit folgendem SQL-Statement:
SELECT to_date("Start Date", 'DD/MM/YY') AS date,
("Distance")::numeric AS distance
FROM smashrun_import;
Der Cast auf numeric ist später noch relevant – beim Import ist das Distance-Feld ein float8 geworden, den PostgreSQL offenbar nicht runden kann. So sehen die Daten dann beispielhaft aus:

Im Screenshot ist bewusst ein Ausschnitt gewählt, der die nächsten Probleme zeigt:
- An manchen Tagen laufe ich gar nicht (8., 9., 10., 12. Juni 2018).
- An machen Tagen laufe ich mehrmals (13. Juni 2018).
Ersteres ist ein Problem, weil dadurch die letzten sieben Zeilen vom 15. Juni aus aufaddiert nicht der Distanz der letzten sieben Tage entsprechen – es sind die letzten sieben Läufe. Das ist aber lösbar: generate_series() kann eine vollständige Liste aller Tage zwischen dem allerersten Lauf in den Daten (SELECT MIN(date) FROM runs) und dem heutigen Tag (NOW()) erzeugen. Per RIGHT JOIN verknüpfen wir diese Liste mit den tatsächlichen Daten. COALESCE() setzt dann an Tagen, die keinen Distance-Wert enthalten (also an denen ich nicht gelaufen bin) einfach eine 0 ein.
Das vollständige SQL-Statement dazu sieht so aus:
SELECT
date_series::date,
COALESCE(runs.distance, 0) AS distance_per_day
FROM
runs
RIGHT JOIN generate_series(
(SELECT MIN(date) FROM runs),
NOW(),
'1 day') date_series
ON date_series::date = runs.date
Und das Ergebnis, wieder beginnend mit dem Datum aus dem obigen Screenshot:

Schon besser – bleibt nur noch das zweite Problem, Tage mit mehreren Läufen. Ein wesentlich einfacherer SQL-Trick: Die Distance-Werte desselben Tages aufsummieren und dann die gruppierten Werte pro Tag ausgeben. Das obige SQL-Statement wird um die Gruppierung (GROUP BY in der letzten Zeile) und das Aufsummieren (SUM() in der dritten Zeile) ergänzt:
SELECT
date_series::date,
SUM(COALESCE(runs.distance, 0)) AS distance_per_day
FROM
runs
RIGHT JOIN generate_series(
(SELECT MIN(date) FROM runs),
NOW(),
'1 day') date_series
ON date_series::date = runs.date
GROUP BY date_series::date
Die Liste enthält nun alle Tage seit dem ersten Lauf, jeden Tag aber nur ein Mal. An Tagen mit mehreren Läufen ist die Distanz aufsummiert, an Tagen ohne Lauf null:
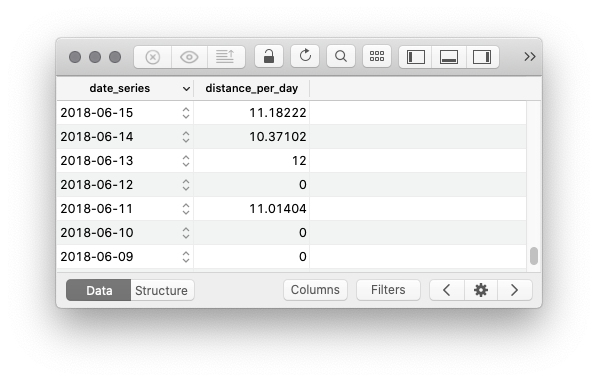
Jetzt wo die Daten ordentlich vorbereitet sind, kann die eigentliche Auswertung kommen. Wir bilden eine Liste, in der für jedes Datum die aufsummierten Distanzen des Tages selbst und der sechs Tage davor (was Dank der Aufbereitung jetzt sechs Tabellenzeilen davor bedeutet!) berechnet wird. Sortiert man diese Liste dann nach dieser aufsummierten Distanzen, ist das Enddatum der weitesten Woche gefunden.
Aufsummiert wird wieder mit SUM(), diesmal allerdings nicht anhand einer Gruppierung, sondern anhand einer sogenannten window function, ein sehr mächtiges SQL-Werkzeug.2 Das finale SQL-Statement in “normalem” Deutsch beschrieben: Schnapp dir alle Tage (date) und die auf zwei Nachkommastellen gerundeten Distanzsummen (total_distance) basierend auf der bereinigten Tabelle im letzten Schritt (days). Bilde die Distanzsumme eines Tages jeweils als Summe der Distanzen aller Tage, die zwischen sechs Tagen vor diesem Tag und null Tagen vor diesem Tag liegen. Sortiere diese Liste anhand der Distanzsummen.
SELECT
date,
ROUND(
SUM(distance_per_day) OVER (
ORDER BY date ROWS BETWEEN
6 PRECEDING AND
0 PRECEDING
),
2) AS total_distance
FROM
days
ORDER BY
total_distance DESC
Das endgültige Ergebnis sieht dann wie folgt aus:
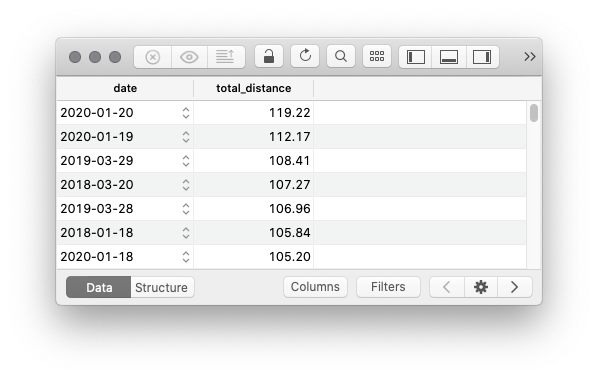
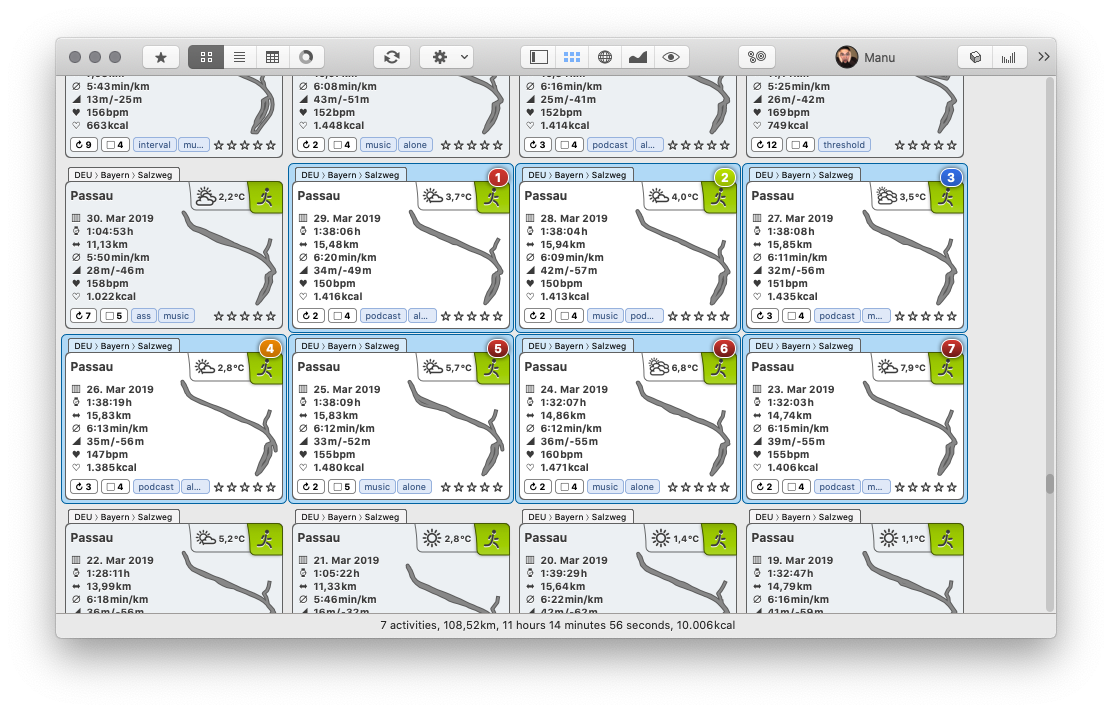
Wie erwartet sind die 119 km der neue Rekord. Sogar die 112 km in der Woche ab dem Vortag wären ein neuer Rekord gewesen – und das war eine Kalenderwoche, also auch in den Auswertungen der normalen Tools wird dieser Jahresauftakt sich eine Weile verewigen. Aber wie man sieht habe ich schon häufig einiges mehr als die bisher bekannten KW-basierten 102 km innerhalb von sieben Tagen geschafft. Natürlich darf die Gegenprobe in meinem primären Werkzeug RubiTrack nicht fehlen. Bis auf leichte Rundungsabweichnungen nach dem Komma stimmen die 108 km im SQL-Ergebnis genau mit der Gesamtdistanz (in der Statusleiste) der entsprechenden, markierten sieben Läufe bis zum 29.03.2019 überein:
Wer es noch nicht kennt: The Problem with Time & Timezones ↩︎
Empfehlenswerter SQL-Talk zu window functions und mehr. ↩︎